“Sonic Pendulum” with Yuri Suzukiの舞台裏 – ミラノデザインウィーク
Recent Posts
先日のミラノデザインウィークで発表したSonic Pendulumについてまとめました.
Yuri Suzukiくんが主体となったインスタレーションに、主にサウンド生成のアルゴリズムの部分で参加しました。
一番最初にYuriくんからこのプロジェクトの話を持ちかけられたときに、「振り子型のスピーカーを並べた音響作品」という大枠のアイデアと「AI」「環境」「人と自然、歴史と先進性のバランス」といった作品を表現するキーワードがいくつかありました.
そんな中、わりとすぐに Autoencoderを使ったらどうかと思いついたのを覚えています.

Autoencoderはニューラルネットワークの一種で、入力したデータをより少ない次元で表現した上で、入力に近いデータを出力するように学習を進めるモデルです. 入力したデータをそのまま出力することにどういう意味があるのかと思われると思いますが、入力したデータをより少ない次元で表現することを学ぶことで、データの中に隠れた構造を学習することが期待できます。
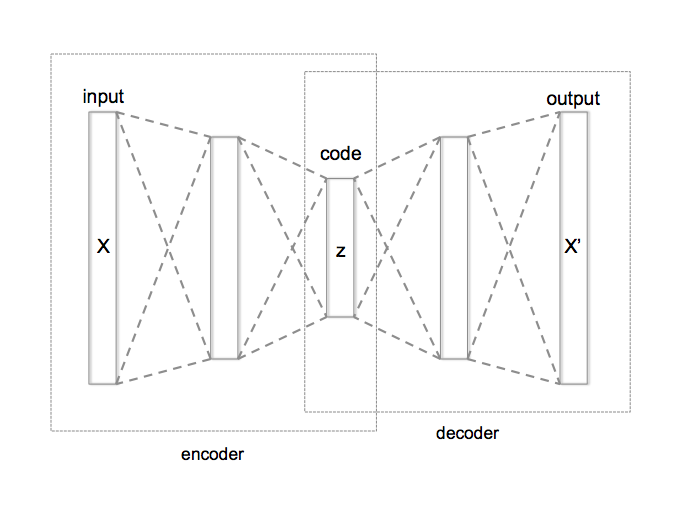
autoencoder 概念図 ( wikipediaより)
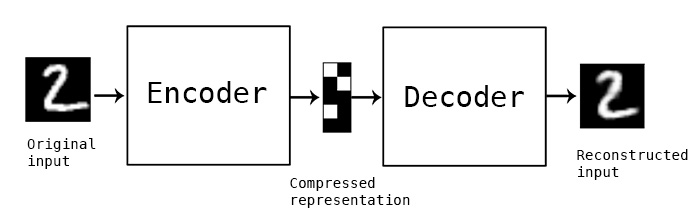
autoencoderをMNISTに応用
(http://blog.keras.io/より)
よくあるMNISTのような数字の認識を思い浮かべてください。この例では、 28x 28ピクセル(784画素)の白黒の画素で表現された数字を入力として、32次元のベクトル(隠れ層)を通して、同じく784画素の白黒画素を出力するモデルになっています。
たとえば「1」という数字。縦線の角度がバラバラでも、ある一定の範囲内であれば、人は1を1として認識できますよね。同様に、「3」にはさまざまな3があったとしても「3らしさ」があるはずです。Autoencoderの32次元の隠れ層のデータには表現された数字は、1が1, 2が2… であるためのエッセンス、1らしさ、2らしさが凝縮されていると言えます。さらに入力に対して人為的なノイズをあらかじめ乗せた上で学習すると(出力はノイズを足す前のデータ)、多少ノイズが乗った画像が入力されても、モデルを通すことでノイズが無い画像を再現することができます(ノイズ除去という意味でdenoising autoencoderと呼ばれます)。

denoising autoencoder
入力にばらつきがあっても出力が一定する = ある種の平衡状態を保つイメージが、振り子のバランスと繰り返す動きのイメージにぴったりくるように思いました。そこでAutoEncoderを使おうと思いついたわけです。
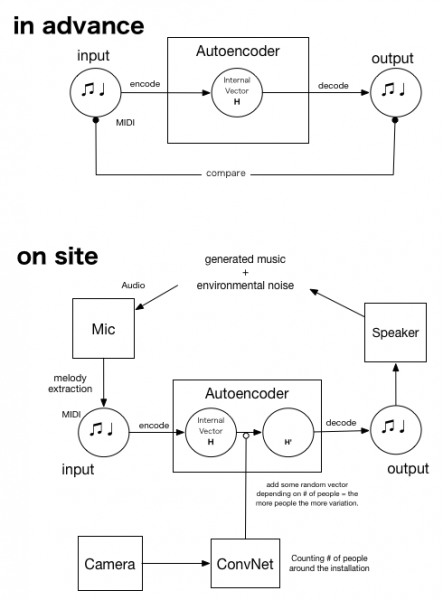
今回、シンプルなAutoencoderをまずはMIDIデータで学習しました。Yuriくんの方で用意したメロディーのMIDIをもとに、時系列データを対象にしたAutoencoder(sequence2sequenceモデル)を学習します。
さらに肝となったのが、マイクの入力からメロディーを抽出するアルゴリズムです. 実際に再生されている音からメロディーを抽出し、次のステップのAutoencoderの入力とします。前述のようにAutoencoderを使うことで、理論的には入力と出力のループをひたすら繰り返すことになるはずですが、スピーカーとマイク、メロディー抽出のアルゴリズムを利用することで、環境ノイズという外的な要因が導入されます。
さらに今回はゆらぎを明示的に導入するトリガーとして、「観客の数」という要素を入れました。写真の中の人の数を認識するために 畳み込みニューラルネットワーク – Convolutional Neural Network (CNN) を利用しました。人数によって、Autoencoderの隠れ層のベクトルにランダムな(小さな)ベクトルを足します。これによって、人が多いほど出力されるメロディーが入力からずれていく=メロディーが揺らぐことになります。(このモデルの詳細についてもどこかで時間を作って書きたいと思います)

会場に安価なwebカメラを設置。日本においたGPUサーバで処理をして人数を返すという処理をしているので、2, 3秒のディレイがありますが (誰もいないところに人影が見えているのはそのせいです)、音楽的な展開をゆるやかに制御するという意味では十分でした。
以上のシステムを概念図にまとめたのが次の図です。上半分は事前準備。下は会場での仕組みです。
ミラノの歴史ある教会が展示会場ということもあり、荘厳な雰囲気のインスタレーションに仕上がったと聞いてます。 聞いてます… と書いたのは、実は別のプロジェクトの締め切りと重なったこともあり、会場に自分自身が行けなかったのです(涙)
dockerでpythonのスクリプトが動く環境を作ってテストし、会場側でpullして使ってもらうというスタイルでの設営でしたが、現地の皆さんの協力でなんとか実施にこぎつけました。特に会場でサウンド及びテクニカル面を仕切ってくださったManabu Shimadaさんに大変お世話になりました!ありがとうございました。
なお、今回のインスタレーションで使っている声は、コーラスの国際コンクールで金賞の受賞歴があるQosmoの細井が担当しています。振り子型スピーカーをつかったマルチチャンネルの処理は、Ray Kunimotoさんにお願いしました。(國本さんの最近のご自身のマルチチャンネルのサウンドインスタレーションも素敵でした!)
Yuriくんとは古くからの付き合いですが、一緒に作品を作ったのは初めての経験でした. 僕にとってもよい勉強になりました。どこか日本でも展示したいねという話をしています!
Recent Posts
Featured Articles